
小红书视频解析源码
 摘要:
仅供学习研究仅用于技术学习和原理探究,旨在了解后端API交互和数据处理方式,尊重版权:请勿将此技术用于任何商业用途或侵犯他人版权的行为,小红书的视频内容受版权保护,请通过官方渠道观...
摘要:
仅供学习研究仅用于技术学习和原理探究,旨在了解后端API交互和数据处理方式,尊重版权:请勿将此技术用于任何商业用途或侵犯他人版权的行为,小红书的视频内容受版权保护,请通过官方渠道观... 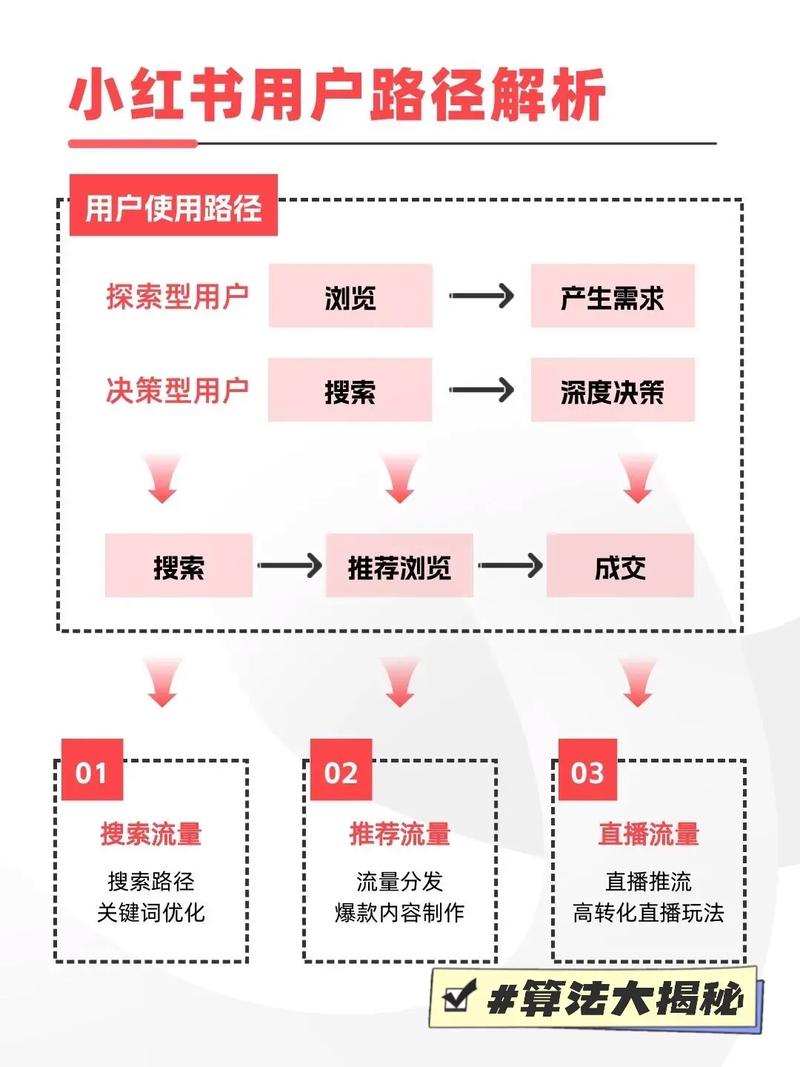
- 仅供学习研究仅用于技术学习和原理探究,旨在了解后端API交互和数据处理方式。
- 尊重版权:请勿将此技术用于任何商业用途或侵犯他人版权的行为,小红书的视频内容受版权保护,请通过官方渠道观看和下载。
- 反爬虫机制:小红书有非常严格的反爬虫和反盗链机制,直接解析或下载视频可能会触发风控,导致IP被封禁或账号受限,以下代码仅为示例,在实际环境中可能很快失效。
核心原理
小红书视频解析的核心原理是模拟客户端(如手机App或浏览器)向后端服务器发送请求,获取视频的真实播放地址,这个过程通常分为以下几个步骤:
- 获取视频ID:从小红书分享链接中提取出视频的唯一标识符。
- 构造请求:模拟App的请求头和参数,向小红书的API服务器发送一个获取视频信息的请求。
- 解析响应:服务器会返回一个JSON或XML格式的数据包,里面包含了视频的详细信息,其中最重要的就是视频的真实播放地址(URL)。
- 下载视频:使用获取到的真实地址,通过HTTP请求下载视频文件。
源码解析(Python示例)
我们将使用Python语言,结合requests库来模拟网络请求,re库来解析URL,json库来处理响应数据。
分析小红书视频链接
小红书视频分享链接的格式通常如下:
https://www.xiaohongshu.com/explore/xxxxxxxxxxxxxx
xxxxxxxxxxxxxx就是视频的唯一ID,我们的第一步就是从这个链接中提取出这个ID。
import re
def extract_video_id(url):
"""
从小红书分享链接中提取视频ID
"""
# 使用正则表达式匹配
# 匹配 /explore/ 后面跟着的一串字符
pattern = r'/explore/([a-zA-Z0-9]+)'
match = re.search(pattern, url)
if match:
return match.group(1)
else:
raise ValueError("无法从URL中提取视频ID,请检查URL格式。")
# 示例URL
example_url = "https://www.xiaohongshu.com/explore/6Z2GXxwY8nK8m5uE3fQ9bA"
video_id = extract_video_id(example_url)
print(f"提取到的视频ID: {video_id}")
模拟App请求获取视频信息
这是最关键的一步,我们需要找到小红书App在播放视频时调用的API接口,通过抓包工具(如Charles或Fiddler)可以分析出App的网络请求。
经过分析,小红书App在获取视频详情时,通常会调用一个类似https://www.xiaohongshu.com/discovery/item/v1/{video_id}的接口。
请求的关键点:
-
请求头:必须模拟App的请求头,否则服务器会拒绝请求,最重要的几个头是:
User-Agent:伪装成手机App。X-Secsdk-Csrf-Token:一个动态的防CSRF令牌,通常在App启动时获取。X-Secsdk-csrf-platform:平台标识,如android或ios。- 其他可能的头,如
X-Requested-With、Accept-Language等。
-
请求参数:API通常需要一些参数,比如
source、extra等,这些也可能在抓包时被发现。
由于X-Secsdk-Csrf-Token等动态令牌的获取非常复杂且随时可能变化,我们的示例代码会先省略它,或者使用一个可能已经失效的静态值来展示逻辑。
import requests
import json
def get_video_info(video_id):
"""
模拟App请求,获取视频信息
"""
# API URL
api_url = f"https://www.xiaohongshu.com/discovery/item/v1/{video_id}"
# 请求头 - 这是关键!必须模拟App
# 注意:下面的User-Agent和Token是示例,很可能已经失效
headers = {
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 15_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.6 Mobile/15E148 Safari/604.1",
"X-Requested-With": "XMLHttpRequest",
"Accept": "application/json, text/plain, */*",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"X-Secsdk-Csrf-Token": "YOUR_CSRF_TOKEN_HERE", # 动态令牌,获取困难
"X-Secsdk-csrf-platform": "android",
"Referer": f"https://www.xiaohongshu.com/explore/{video_id}"
}
try:
# 发送GET请求
response = requests.get(api_url, headers=headers, timeout=10)
# 检查请求是否成功
response.raise_for_status()
# 解析JSON响应
data = response.json()
if data.get('status') == 0:
return data.get('data')
else:
print(f"API请求失败: {data.get('msg')}")
return None
except requests.exceptions.RequestException as e:
print(f"网络请求出错: {e}")
return None
except json.JSONDecodeError:
print("响应解析失败,返回的不是有效的JSON格式")
return None
# 使用上一步提取的ID
video_data = get_video_info(video_id)
if video_data:
print("成功获取视频信息!")
# print(json.dumps(video_data, indent=2, ensure_ascii=False)) # 打印完整信息
从响应数据中解析视频URL
现在我们拿到了video_data,这是一个字典,我们需要在其中找到视频的播放地址,视频地址可能嵌套在note_card -> video -> play_addr -> url_list中。
def extract_video_url(video_data):
"""
从视频信息数据中解析出视频的真实播放地址
"""
if not video_data:
return None
# 根据实际的数据结构进行解析
# 这是最常见的路径,但小红书可能会随时修改
try:
# 真实视频地址通常是一个列表,取第一个即可
video_url_list = video_data['note_card']['video']['play_addr']['url_list']
if video_url_list:
# url_list 里的地址通常是带防盗链的,可以直接下载
return video_url_list[0]
except KeyError:
print("数据结构已变更,无法解析视频URL。")
# 尝试其他可能的路径
# e.g., video_data['item_info']['item_struct']['video']['play_addr']['url_list']
return None
if video_data:
video_url = extract_video_url(video_data)
if video_url:
print(f"解析到的视频播放地址: {video_url}")
else:
print("未能解析到视频地址。")
下载视频文件
我们使用获取到的真实地址来下载视频,由于视频文件可能很大,我们需要使用流式下载,避免一次性占用过多内存。
def download_video(video_url, save_path="xiaohongshu_video.mp4"):
"""
下载视频文件
"""
print(f"开始下载视频到: {save_path}")
try:
# 使用 stream=True 进行流式下载
with requests.get(video_url, stream=True, timeout=30) as r:
r.raise_for_status()
# 获取文件总大小(字节)
total_size = int(r.headers.get('content-length', 0))
# 打开文件,以二进制写入模式
with open(save_path, 'wb') as f:
# 已下载大小
downloaded_size = 0
# 设置块大小
chunk_size = 8192
for chunk in r.iter_content(chunk_size=chunk_size):
if chunk: # 过滤掉保持连接的新块
f.write(chunk)
downloaded_size += len(chunk)
# 打印下载进度
if total_size > 0:
progress = (downloaded_size / total_size) * 100
print(f"\r下载进度: {progress:.2f}%", end='')
print("\n下载完成!")
return True
except requests.exceptions.RequestException as e:
print(f"\n下载失败: {e}")
return False
if video_url:
download_video(video_url)
完整整合代码
将以上所有步骤整合到一个完整的脚本中:
import re
import requests
import json
import os
# --- 配置 ---
# 请替换为你要解析的小红书视频链接
TARGET_URL = "https://www.xiaohongshu.com/explore/6Z2GXxwY8nK8m5uE3fQ9bA"
# 视频保存路径
SAVE_PATH = "xiaohongshu_video.mp4"
# --- 函数定义 ---
def extract_video_id(url):
"""从URL提取视频ID"""
pattern = r'/explore/([a-zA-Z0-9]+)'
match = re.search(pattern, url)
if match:
return match.group(1)
raise ValueError("无效的URL格式,无法提取视频ID。")
def get_video_info(video_id):
"""模拟App请求,获取视频信息"""
api_url = f"https://www.xiaohongshu.com/discovery/item/v1/{video_id}"
headers = {
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 15_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.6 Mobile/15E148 Safari/604.1",
"X-Requested-With": "XMLHttpRequest",
"Accept": "application/json, text/plain, */*",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
# 注意:这个Token是动态的,通常很难获取,这里的值很可能已失效。
"X-Secsdk-Csrf-Token": "YOUR_CSRF_TOKEN_HERE",
"X-Secsdk-csrf-platform": "android",
"Referer": f"https://www.xiaohongshu.com/explore/{video_id}"
}
try:
response = requests.get(api_url, headers=headers, timeout=10)
response.raise_for_status()
data = response.json()
if data.get('status') == 0:
return data.get('data')
print(f"API返回错误: {data.get('msg')}")
return None
except Exception as e:
print(f"请求或解析数据时出错: {e}")
return None
def extract_video_url(video_data):
"""从数据中解析视频URL"""
if not video_data:
return None
try:
# 这是一个常见的路径,但可能变化
return video_data['note_card']['video']['play_addr']['url_list'][0]
except (KeyError, TypeError, IndexError):
print("数据结构已变更,无法解析视频URL。")
return None
def download_video(video_url, save_path):
"""下载视频"""
if os.path.exists(save_path):
print(f"文件 {save_path} 已存在,跳过下载。")
return
print(f"开始下载视频到: {save_path}")
try:
with requests.get(video_url, stream=True, timeout=60) as r:
r.raise_for_status()
total_size = int(r.headers.get('content-length', 0))
with open(save_path, 'wb') as f:
downloaded_size = 0
for chunk in r.iter_content(chunk_size=32768):
if chunk:
f.write(chunk)
downloaded_size += len(chunk)
if total_size > 0:
progress = (downloaded_size / total_size) * 100
print(f"\r下载进度: {progress:.2f}%", end='', flush=True)
print("\n下载完成!")
except Exception as e:
print(f"\n下载失败: {e}")
if os.path.exists(save_path):
os.remove(save_path) # 删除未下载完的文件
# --- 主程序 ---
if __name__ == "__main__":
print("小红书视频解析器启动...")
try:
video_id = extract_video_id(TARGET_URL)
print(f"视频ID: {video_id}")
video_data = get_video_info(video_id)
if not video_data:
print("获取视频信息失败,程序退出。")
exit()
video_url = extract_video_url(video_data)
if not video_url:
print("解析视频URL失败,程序退出。")
exit()
print(f"获取到视频地址: {video_url}")
download_video(video_url, SAVE_PATH)
except Exception as e:
print(f"程序运行出错: {e}")
总结与挑战
- 动态令牌:最大的挑战是获取
X-Secsdk-Csrf-Token等动态请求头,这些令牌通常通过App启动时的复杂登录或握手流程获取,逆向工程难度极高。 - API变化:小红书会不定期更新其后端API和数据结构,导致解析代码失效,这需要持续地进行抓包分析和代码维护。
- 防盗链:视频URL本身可能带有防盗链参数,直接下载可能会被服务器拒绝,通常需要携带特定的
Referer等请求头。 - 法律风险:绕过平台机制获取数据,可能违反用户协议和相关法律法规。
这个源码解析更多的是一种技术学习和探索,对于个人用户,最合规、最方便的方式仍然是使用小红书官方App或网页版进行观看。
作者:99ANYc3cd6本文地址:https://chumoping.net/post/22022.html发布于 01-31
文章转载或复制请以超链接形式并注明出处初梦运营网







